UniversalCEFR: Enabling Open Multilingual Research on Language Proficiency Assessment
Presented at EMNLP 2025 (Main)

Contact: jmri20@bath.ac.uk, alvamanchegof@cardiff.ac.uk
Contact: jmri20@bath.ac.uk, alvamanchegof@cardiff.ac.uk
Language proficiency assessment is foundational to advancing educational research and many natural language processing (NLP) applications, particularly for tasks like automatic readability assessment (ARA) and automated essay scoring (AES). The Common European Framework of Reference for Languages or CEFR is one of the most globally recognized frameworks for standardised assessment of proficiency across different languages and countries. However, despite CEFR's role as the de facto framework, most language proficiency assessment datasets based on the CEFR suffer from several access and interoperability limitations:
We introduce UniversalCEFR, a large, standardised, open, multilingual dataset of CEFR-labeled texts for language proficiency assessment research, consolidated from 26 existing corpora and accessible for non-commercial research. It brings together 505,807 texts labeled with CEFR levels across 13 languages and 4 scripts (Latin, Cyrillic, Arabic, and Devanagari).
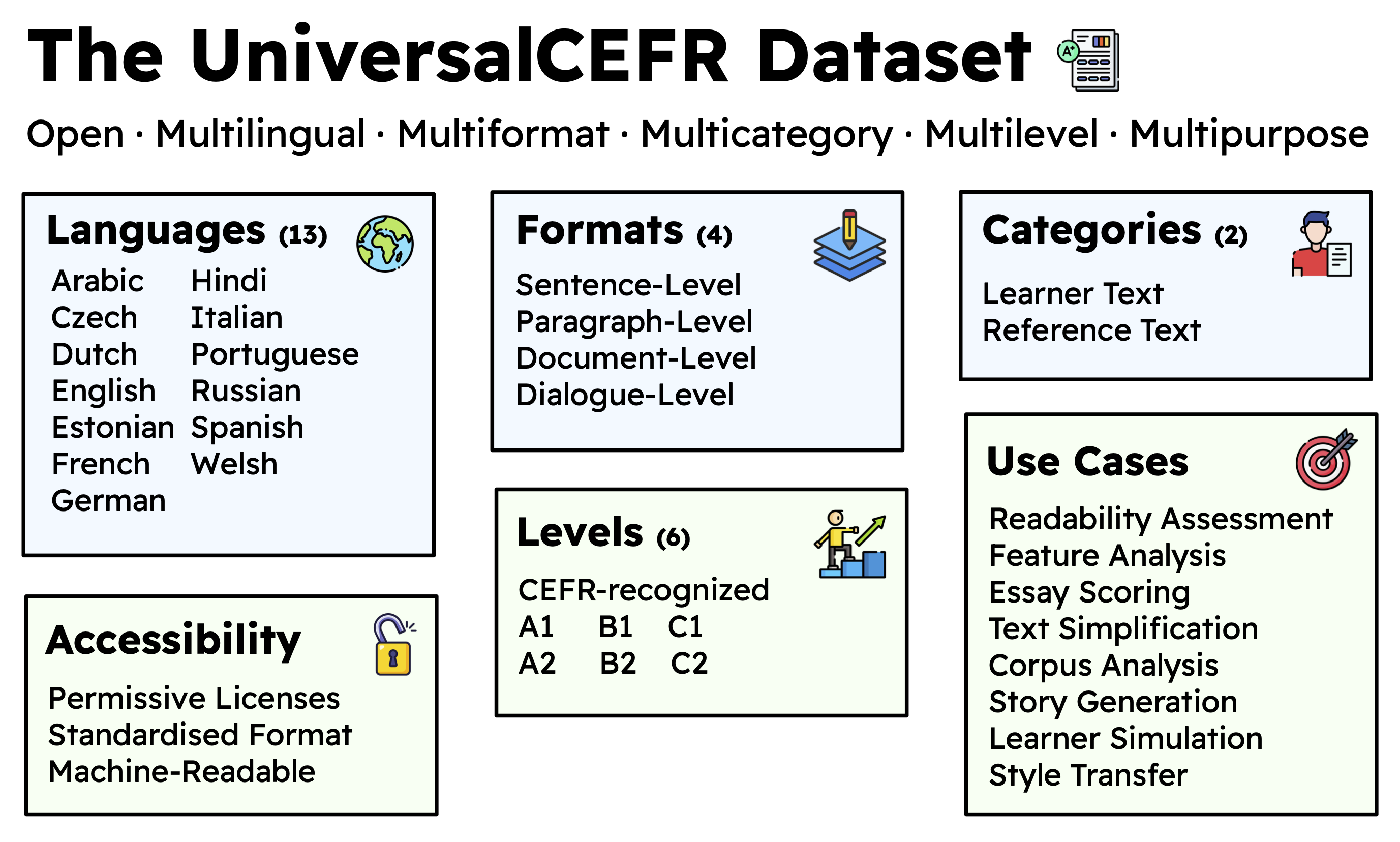
The dataset includes various text categories including learner texts (e.g., essays, writing samples) and reference texts (e.g., curated reading materials); diverse text-level granularities including sentence, paragraph, document, and dialogue levels; and full CEFR scale coverage from A1 to C2.
For UniversalCEFR, we use a structured and standardised JSON format containing necessary per-instance information in the form of eight (8) metadata fields for each CEFR-labelled texts included in the dataset. The table below lists the text fields, descriptions, and examples for each field. All instances that were validated and included in the collection of CEFR-labelled corpora for UniversalCEFR conform to this format.
| Field | Description |
|---|---|
title |
The unique title of the text retrieved from its original corpus (NA if there are no titles such as CEFR-assessed sentences or paragraphs). |
lang |
The source language of the text in ISO 639-1 format (e.g., en for English). |
source_name |
The source dataset name where the text is collected as indicated from their source dataset, paper, and/or documentation (e.g., cambridge-exams from Xia et al. (2016)). |
format |
The format of the text in terms of level of granularity as indicated from their source dataset, paper, and/or documentation. The recognized formats are the following: document-level, paragraph-level, discourse-level, sentence-level. |
category |
The classification of the text in terms of who created the material. The recognized categories are reference for texts created by experts, teachers, and language learning professionals and learner for texts written by language learners and students. |
cefr_level |
The CEFR level associated with the text. The six recognized CEFR levels are the following: A1, A2, B1, B2, C1, C2. |
license |
The licensing information associated with the text (e.g., CC-BY-NC-SA 4.0). |
text |
The actual content of the text itself. |
The current compilation for UniversalCEFR is composed of 26 CEFR-labeled publicly-accessible corpora which can be used for non-commercial research and derivations can be created as long as it follows the same license.
We provide an informative data directory covering language proficiency-based information including the language, format, category, annotation method, distinct L1 learners, inter-annotator agreeement, and license information about the compiled datasets that may be useful for the utility of UniversalCEFR.
| Corpus Name | Lang (ISO 638-1) | Format | Category | Size | Annotation Method | Expert Annotators | Distinct L1 | Inter-Annotator Agreement | CEFR Coverage | License | Resource |
|---|---|---|---|---|---|---|---|---|---|---|---|
| cambridge-exams | en | document-level | reference | 331 | n/a | n/a | n/a | n/a | A1-C2 | CC BY-NC-SA 4.0 | Xia et al. (2016) |
| elg-cefr-en | en | document-level | reference | 712 | manual | 3 | n/a | n/a | A1-C2, plus | CC BY-NC-SA 4.0 | Breukker (2022) |
| cefr-sp | en | sentence-level | reference | 17,000 | manual | 2 | n/a | r = 0.75, 0.73 | A1-C2 | CC BY-NC-SA 4.0 | Arase et al. (2022) |
| elg-cefr-de | de | document-level | reference | 509 | manual | 3 | n/a | n/a | A1-C2 | CC BY-NC-SA 4.0 | Breukker (2022) |
| elg-cefr-nl | nl | document-level | reference | 3,596 | manual | 3 | n/a | n/a | A1-C2, plus | CC BY-NC-SA 4.0 | Breukker (2022) |
| icle500 | en | document-level | learner | 500 | manual | 28 | ur, pa, bg, zh, cs, nl, fi, fr, de, el, hu, it, ja, ko, lt, mk, no, fa, pl, pt, ru, sr, es, sv, tn, tr | Rasch kappa = -0.02 | A1-C2, plus | CC0 1.0 | Thwaites et al. (2024) |
| cefr-asag | en | paragraph-level | learner | 299 | manual | 3 | fr | Krippendorf alpha = 0.81 | A1-C2 | CC BY-NC-SA 4.0 | Tack et al. (2017) |
| merlin-cs | cs | paragraph-level | learner | 441 | manual | multiple | hu, de, fr, ru, pl, en, sk, es | n/a | A2-B2 | CC BY-SA 4.0 | Boyd et al. (2014) |
| merlin-it | it | paragraph-level | learner | 813 | manual | multiple | hu, de, fr, ru, pl, en, sk, es | n/a | A1-B1 | CC BY-SA 4.0 | Boyd et al. (2014) |
| merlin-de | de | paragraph-level | learner | 1,033 | manual | multiple | hu, de, fr, ru, pl, en, sk, es | n/a | A1-C1 | CC BY-SA 4.0 | Boyd et al. (2014) |
| hablacultura | es | paragraph-level | reference | 710 | manual | multiple | n/a | n/a | A2-C1 | CC BY NC 4.0 | Vasquez-Rodrigues et al. (2022) |
| kwiziq-es | es | document-level | reference | 206 | manual | multiple | n/a | n/a | A1-C1 | CC BY NC 4.0 | Vasquez-Rodrigues et al. (2022) |
| kwiziq-fr | fr | document-level | reference | 344 | manual | multiple | n/a | n/a | A1-C1 | CC BY NC 4.0 | Original |
| caes | es | document-level | learner | 30,935 | computer-assisted | multiple | pt, zh, ar, fr, ru | n/a | A1-C1 | CC BY NC 4.0 | Vasquez-Rodrigues et al. (2022) |
| deplain-web-doc | de | document-level | reference | 394 | manual | 2 | n/a | Cohen kappa = 0.85 | A1,A2,B2,C2 | CC-BY-SA-3, CC-BY-4, CC-BY-NC-ND-4 | Stodden et al. (2023) |
| deplain-apa-doc | de | document-level | reference | 483 | manual | 2 | n/a | Cohen kappa = 0.85 | A2-B1 | CC-BY-SA-3, CC-BY-4, CC-BY-NC-ND-4 | Stodden et al. (2023) |
| deplain-apa-sent | de | sentence-level | reference | 483 | manual | 2 | n/a | n/a | A2-B2 | By request | Stodden et al. (2023) |
| elle | et | paragraph-level, document-level | learner | 1,697 | manual | 2 | n/a | n/a | A2-C1 | CC BY 4.0 | Vajjala and Rama (2018) |
| efcamdat-cleaned | en | sentence-level, paragraph-level | learner | 406,062 | manual | n/a | br, zh, tw, ru, sa, mx, de, it, fr, jp, tr | n/a | A1-C1 | Cambridge | Geertzen et al. (2013) |
| beast2019 | en | sentence-level | learner | 3,600 | manual | multiple | n/a | n/a | A1-C2 | CC BY SA NC 4.0 | Bryant et al. (2019) |
| peapl2 | pt | paragraph-level | learner | 481 | manual | n/a | zh, en, es, de, ru, fr, ja, it, nl, ar, pl, ko, ro, sv | n/a | A1-C2 | CC BY SA NC 4.0 | Martins et al. (2019) |
| cople2 | pt | paragraph-level | learner | 942 | manual | n/a | zh, en, es, de, ru, fr, ja, it, nl, ar, pl, ko, ro, sv | n/a | A1-C1 | CC BY SA NC 4.0 | Mendes et al. (2016) |
| zaebuc | ar | paragraph-level | learner | 214 | manual | 3 | en | Unnamed kappa = 0.99 | A2-C1 | CC BY SA NC 4.0 | Habash and Palfreyman (2022) |
| readme | ar, en, fr, hi, ru | sentence-level | reference | 9,757 | computer-assisted | 2 | n/a | Krippendorf kappa = 0.67,0.78 | A1-C2 | CC BY SA NC 4.0 | Naous et al. (2024) |
| apa-lha | de | document-level | reference | 3,130 | n/a | n/a | n/a | n/a | A2-B1 | Public | Spring et al. (2021) |
| learn-welsh | cy | document-level, sentence-level, discourse-level | reference | 1,372 | manual | n/a | n/a | n/a | A1-A2 | Public | UniversalCEFR (Original) |
Beyond its data and technical contributions, UniversalCEFR also carries broader sociolinguistic significance. UniversalCEFR addresses the growing linguistic inequality in modern AI development through focusing on under-represented languages alongside English.
We also hope this initiative can lead to more responsible AI development that actively resists the growing linguistic centralization around English in global AI research—a modern Matthew effect—where well-resourced languages receive disproportionate technological attention while smaller languages (like Czech or Welsh) are left behind. The UniversalCEFR is a strong step towards mitigating the Matthew effect
We want to grow this community of researchers, language experts, and educators to further advance openly accessible CEFR and language proficiency assessment corpora for all. If you're interested in this direction, please feel free to join the Huggingface and Github Organizations in the links above.
Moreover, if you have corpora or datasets you want to add to UniversalCEFR for better exposure and utility to researchers around the world, please fill up this form.
When we index your dataset to UniversalCEFR, we will cite you and the paper or project from which the dataset came across the UniversalCEFR platforms. The ownership and copyright of any dataset indexed in UniversalCEFR remain with original data creators.
@article{imperial2025universalcefr,
title = {{UniversalCEFR: Enabling Open Multilingual Research on Language Proficiency Assessment}},
author = {Joseph Marvin Imperial and Abdullah Barayan and Regina Stodden and Rodrigo Wilkens and Ricardo Muñoz Sánchez and Lingyun Gao and Melissa Torgbi and Dawn Knight and Gail Forey
and Reka R. Jablonkai and Ekaterina Kochmar and Robert Reynolds and Eugénio Ribeiro and Horacio Saggion and Elena Volodina and Sowmya Vajjala and Thomas François and Fernando Alva-Manchego and Harish Tayyar Madabushi},
journal = {arXiv preprint arXiv:2506.01419},
year = {2025},
url = {https://arxiv.org/abs/2506.01419}}